Comet.ml で機械学習のログをクラウドに保存する
この記事は CAMPHOR-アドベントカレンダー2020 6日目の記事です。
みなさんこんにちは、ほないです。
私は今年度から大学で自然言語処理の研究に取り組んでいて、データセットを作ってニューラル言語モデルをトレーニングして評価する機会がたくさんありました。
最近はPyTorch, TensorFlow, scikit-learnなど様々な機械学習フレームワークによって、ニューラルネットワークモデルの実装が簡単に行えるようになっています。
今回は、そういったフレームワークで機械学習をするときに便利なサービス「Comet」について紹介します。
機械学習とログと可視化
研究などで機械学習をするときに大切なのが、記録(ログ)を取ること、そしてグラフなどで可視化することです。
記録といっても、ただテスト結果をPrintして終わりというわけにはいきません。
どのデータセットを使ったか、モデルの構成はどうしたか、パラメータは何に設定したかなど、結果に影響する様々な情報を記録しておかないと、後から苦労することになります。 さらに、いろんな情報を記録するといっても、標準出力なのか、ファイルなのか、Jupyter Notebookなのか、 そしてファイルの保存場所はどうするか、万が一に備えてバックアップをどうするかなど、 考えるべきことはたくさんあります。
結果をファイルに保存していたのに、後から設定や条件を思い出せなくてもう一度やり直した、というような経験が私には何回もあります。
可視化も厄介な問題です。
フレームワークが可視化の機能を備えていることも多いですが、 「複数回コードを実行して、ログをファイルに保存し、後からそれを読み込んでグラフを描画する」というような状況では、自前で実装が必要となる場面もあります。 論文に掲載するための図ならまだしも、自分でざっと比較するためにあまり時間をかけたくはないと思います。
そんな機械学習にありがちな不便さを解決してくれるサービスを紹介します。
Comet とは
Comet は、 データサイエンティストや研究者のための、機械学習の記録・可視化のためのサービス です。
CAMPHOR-のアドベントカレンダーからこれを見ている人はWeb系に詳しい人も多いと思うので、そういう人向けに説明するとすれば、 REST APIでクラウドに数値やアセットを保存し、Webサイト上でチャートを描画できるSaaSで、機械学習に特化した機能をもつ というと分かりやすいかもしれません。 REST APIのクライアントとして、Python / Java / R のSDKや、コマンドラインのツールが公開されています。
数行のコードで、機械学習の様々な数値やアセットをクラウドに保存し、 Webサイト上でリアルタイムに閲覧したり、複数の実験を比較したりすることができます。
クラウドに保存されるので、万が一手元のログを消してしまっても問題ありません。
基本用語
Cometでは、Project -> Experiment という単位で記録を行います。 コードを1回実行するのが1 Experimentとして記録されるので、 例えば「MNIST」というProjectを作って、モデルやパラメータなどを変えて何回かコードを実行したExperimentを、後から比較する、という使い方ができます。
インターフェース
CometのUIをサンプルプロジェクトのスクリーンショットで紹介します。
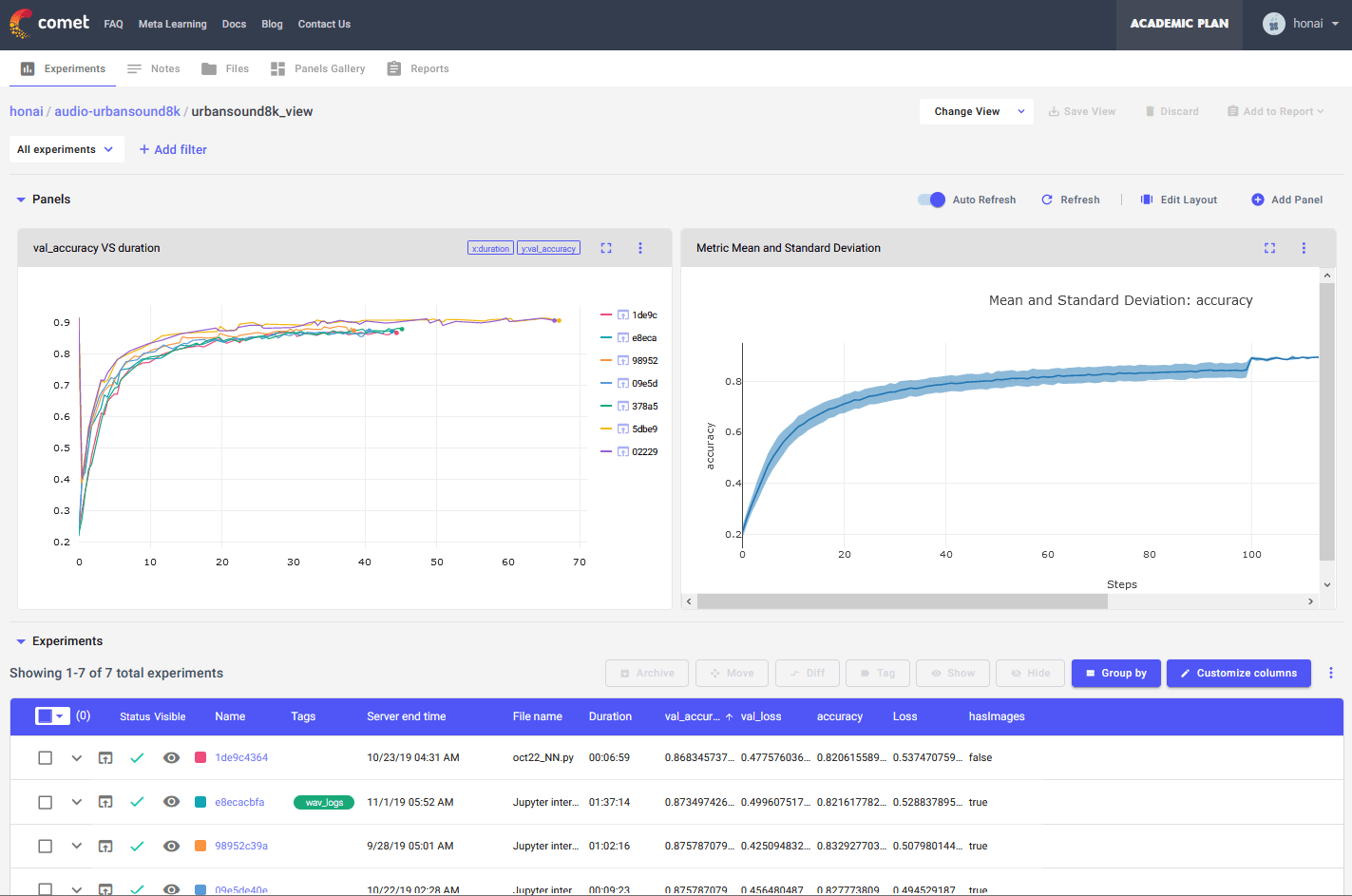


このように、lossや精度を可視化したり、複数のExperimentを比較したり、 画像や音声などのアセットをアップロードして閲覧したりすることができます。 一見複雑なUIですが、直感的に使うことができ、グラフの描画もExcelのようにマウス操作で行うことができます。
Python SDK
Cometの魅力は、多機能なのにSDKは簡単に使えるということにあります(Java, RのSDKもあります)。 使っているフレームワークを問わず、 既存の機械学習のコードにCometによるログを追加することが文字通り数行でできるので、 機械学習の記録や可視化で悩んでいる人はすぐに使い始めることができます。
以下は使い方を簡単にまとめたものですが、詳しくは公式ドキュメントの Python Getting Started などを見てください。
pipなどでComet SDKをインストールします。
Cometのアカウントを登録して、設定画面からAPI Keyをコピーし、環境変数 COMET_API_KEY として設定しておきます。そしてメインのPythonコードでSDKをインポートし初期化します。
from comet_ml import Experiment
experiment = Experiment()
# トレーニングやテストのコード
実はこの2行だけで、Projectの中にExperimentが作成され、
- Pythonのスクリプト / Jupyter Notebook のコード
- コマンドライン引数 (注1)
- 標準出力やNotebookの出力
- GPUやCPU、OSなどの情報
が自動で記録され、さらに対応するフレームワークを使っていれば
- モデルのハイパーパラメータ
- モデルの重みとバイアス
- トレーニングのloss
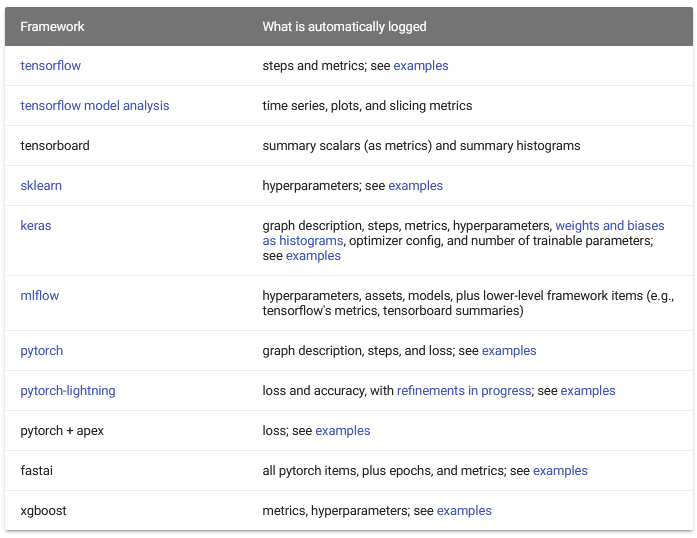
などが自動で記録されます。詳しくはこの表を見てください ↓
さらにValidation Loss, Test Accuracyなど記録したい指標は
y_predict_test = model.predict(x_test)
test_accuracy = compute_accuracy(y_predict_test)
experiment.log_metric('test accuracy', test_accuracy)
のように、 log_metric で好きな名前を付けて自由に記録することができます。
EpochやStepは対応するフレームワークなら勝手に認識してくれるので、
とりあえずループの中で log_metric しておけば後から横軸をStepにして変化をグラフにすることができます。
log_metric 以外にも、
log_assetlog_audiolog_confusion_matrixlog_figure(Pyplotのfigureを記録してくれる)log_histogramlog_htmllog_image
など文字通り「なんでも」記録することができます。
注1 個人的に便利だったのが、実行したPythonスクリプトを自動で記録する機能です。コマンドライン引数ではなく、コードを書き換えることで条件を変えて実験したときにも、後からその実験の時点でのコードを確認することができます。
価格や制限
無料のIndividualプランがあり、制限はありますが十分使えるプランとなっています(後述)。さらに学生メールで登録できる無料のAcademicプランもあり、学生にやさしいサービスです 😭
Projectはデフォルトでプライベートになり、自分のアカウントでログインしないと閲覧できず、未発表の研究のデータを他人に見られてしまう心配はありません。 無料プランでもProjectやExperimentの数は無制限なので、安心して研究に使うことができます。
Academicプランの場合、Collaboratorを追加して共同で使うこともできます。共同研究や、指導教員にも閲覧してほしい場合などに便利そうです。
Individual / Academicプランに共通する制限としては、画像や音声などのアセットを保存するときのStorageの上限や、同時に実行できるExperimentの数です。後者はIndividualでも50、Academicでは500で、少なくとも私は今のところこの制限が不便だったことはありません(500枚のGPUで並列実行、してみたいですね)。
| 機能 | Individual Plan | Academic Plan |
|---|---|---|
| Storage Limit | 100GB | 100GB |
| チームメンバーの上限 | 1 Member | 制限なし |
| 並行実行の上限 | 50 | 500 |
詳細は Pricing – Comet を確認してください。
まとめ
今回はCometというサービスを紹介しました。 Cometを使えば、簡単に機械学習の記録をクラウドに保存し、可視化したり比較したりすることができます。
明日の CAMPHOR- Advent Calender の担当は、 yosyuaomenww さんです。