連載「入門HTTP」 (4) HTTP/2
CAMPHOR- Day 2020で発表した「入門 HTTP」を連載としてブログに投稿しています。研究やら院試勉強やらに追われて前回からかなり間が空いてしまい、CAMPHOR- Dayから3か月が過ぎてしまいました 😇 第4回の記事となります。
連載について
- HTTP/1.xとKeep Alive
- TLSとHTTP - TLSの概要
- TLSとHTTP - HTTP over TLS
- HTTP/1の課題とHTTP/2(本記事)
- QUICとHTTP/3
この連載全体については 第1回の記事 を参照してください。
本ブログ記事に掲載している画像の無断転載を禁じます。
第4回 HTTP/2
Googleは2009年に「SPDY」というプロトコルを発表し、Google Chromeや自社のサーバーにこれを実装し始めました。 このSPDYがほぼそのままHTTP/2という規格となり、2015年に RFC 7540 として公開されました。
HTTP/2は、プロトコルの実装面はHTTP/1.xと全く互換性がありません。 このことが逆に後方互換性の問題を起きにくくしています。
HTTP/2はTLS上で利用することを前提としている面があり、 前回のTLSについての解説で紹介 したALPNを利用して クライアント・サーバー間でネゴシエートできた場合のみHTTP/2で通信します。
それでは、まずHTTP/1系の課題を見ていきましょう。
HTTP/1.x の課題
まずはいくつかHTTP/1系の課題を挙げていきます。
複数のTCPコネクションの占有と輻輳制御
HTTP/1.1では、基本的に1つのTCP接続で1つのHTTPリクエスト/レスポンスが行われます。 Keep Aliveによって連続的にやりとりできるようになったものの、同時に行えるリクエストは1つです。
ただし、クライアントの複数のポートを利用して、TCP接続を複数はって並列化することはできます。 ブラウザはHTTP/1.1で通信するときは1つのドメインに対して最大6本程度のTCP接続を行っています。 この制限を回避するために、複数のドメインから様々なアセットを配信することで実質的にさらに多くの並列化を図っているWebサイトが存在します。
HTTP通信を並列化するにあたって、TCPのレイヤーで並列化を行うことにはいくつかのデメリットがあります。
(サーバー側の)負荷の増大
TCPで接続を張ると接続ごとにバッファが必要になりますし、誤り検出や再送などの処理も接続ごとに必要です。 Webサーバーは多数のクライアントからの接続をさばかなければいけません。 物理的には単一であるクライアントがたくさんのTCP接続を張ってしまうことで、サーバーのリソースを圧迫し、 各クライアントに対して効率的なリソース配分ができなくなる可能性があります。
輻輳制御の重複による帯域の使用効率低下
インターネットの回線速度や品質は時刻や通信相手(とそこへパケットが運ばれるルート)によって変化します。 また、通信相手の処理能力が低ければたくさんパケットを送っても処理しきれないかもしれません。
このようなインターネットの特性に対処するため、TCPには、輻輳制御の機能があります。 具体的には、接続確立して始めは速度を落として通信し、受信応答が欠落なく返ってくれば 段階的に通信速度を上げていく、というような仕組みで、帯域や互いの処理能力に応じた速度で通信を行えるようになっています。
同じクライアントとサーバー間で、複数張られたTCPコネクションがバラバラに輻輳制御をすると、 帯域を効率的に使えないというようなことが起こりえます。
例えば、 画像Aを取得するためのTCP接続が帯域を使いってやりとりしている最中に、 (スクリプトを実行した結果など)別の画像Bを取得する必要が出てきたとします。 すると2本目のTCP接続が貼られることになりますが、1本目が帯域を使いきっているためすぐには高速で通信できなかったり、 お互いにウインドウサイズ増大→他方のパケットの影響で欠落発生→ウインドウサイズ落とす、という風に 通信速度が振動してしまったりするケースが考えられます。
レイテンシの増大
これは自明ですが、今までの回で説明したようにTCPの接続には1RTTの時間がかかり、 TLSを利用する場合はさらにハンドシェイクに時間がかかります。 同じクライアント・サーバー間での通信にこのようなハンドシェイク処理が重複することは効率が悪いでしょう。
HTTP HoL(Head of Line) ブロッキング
HTTP/1.xの問題点は、先述したように1つのTCP接続で同時に1つのリクエストしか処理できないということです。

Head of Lineブロッキングは、待ち行列の先頭が後続を止めてしまうという意味で、 たとえばいったんサイズの大きいファイルをリクエストしてしまうと、 そのレスポンスが完了するまでTCP接続は占有され、 もっとクリティカルなアセットが必要になったとしても優先的に処理することができません。
HTTP/1系の課題をいくつか挙げました。これらを念頭に置いて、 HTTP/2の解説に入っていきたいと思います。
HTTP/2 の仕組み
バイナリベース
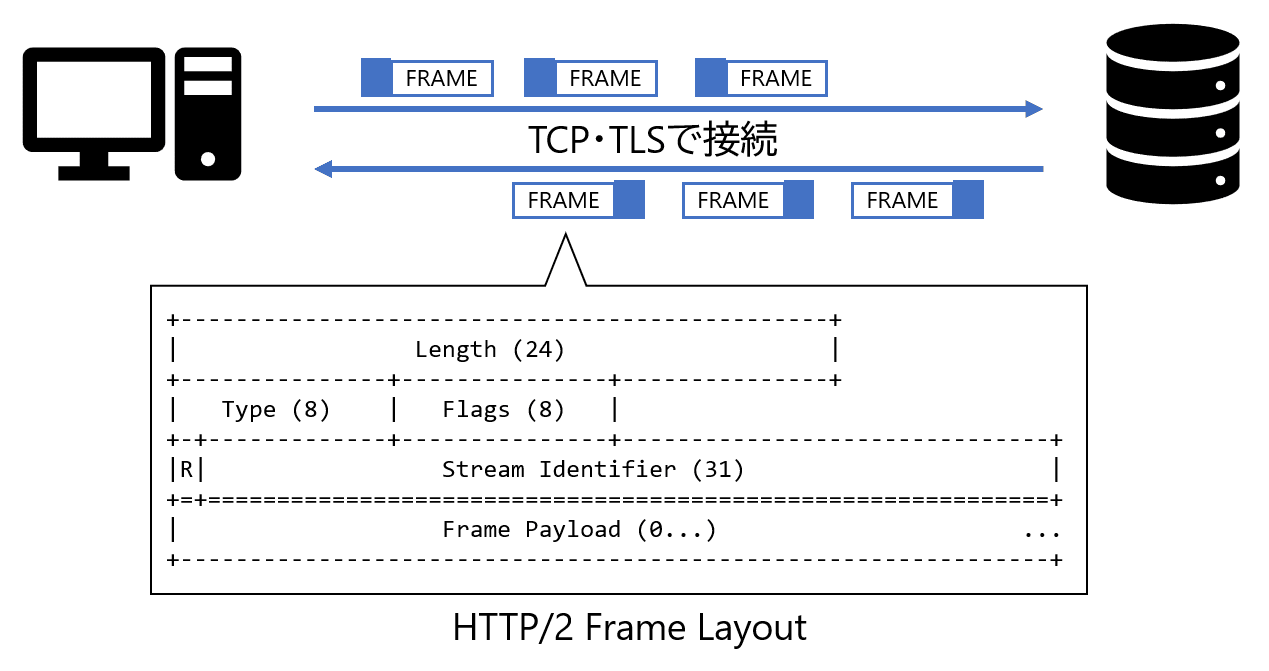
HTTP/2はHTTP/1系と全く互換性がありません。 一番大きな違いはHTTP/2がバイナリベースのプロトコルであるということです。 HTTP/1系では、ヘッダーはASCIIのプレーンテキストで、改行の後にボディがくるというふうに文字列ベースのプロトコルでしたが、 HTTP/2ではバイト列のフォーマットがあらかじめ定められており、HTTPリクエスト・レスポンスをFrameという単位に分割して送信するようになっています。
「互換性がない」といいましたが、HTTP/2の導入によって、アプリケーション層からみたHTTPの使い方が変わるわけではなりません。 TCPあるいはTCPによるバイト列の転送と、高水準のHTTPのAPI(メソッド、ヘッダーなどセマンティック)の間の、 HTTPの表現方法がバイナリフォーマットに変わっただけです。
ストリームによる多重化
HTTP/2では、バイナリフォーマットを採用することで、 1つのTCP/TLS接続上に仮想的に通信路を多重化してやり取りができるようになりました。 これを説明するにあたってまず新しい用語を紹介します。
- フレーム: HTTP/2の通信の最小単位で、ストリームIDが振られている
- メッセージ: 1つのHTTPのリクエストやレスポンスに対応する、フレームの列
- ストリーム: フレームをやり取りする仮想的な双方向の通信路
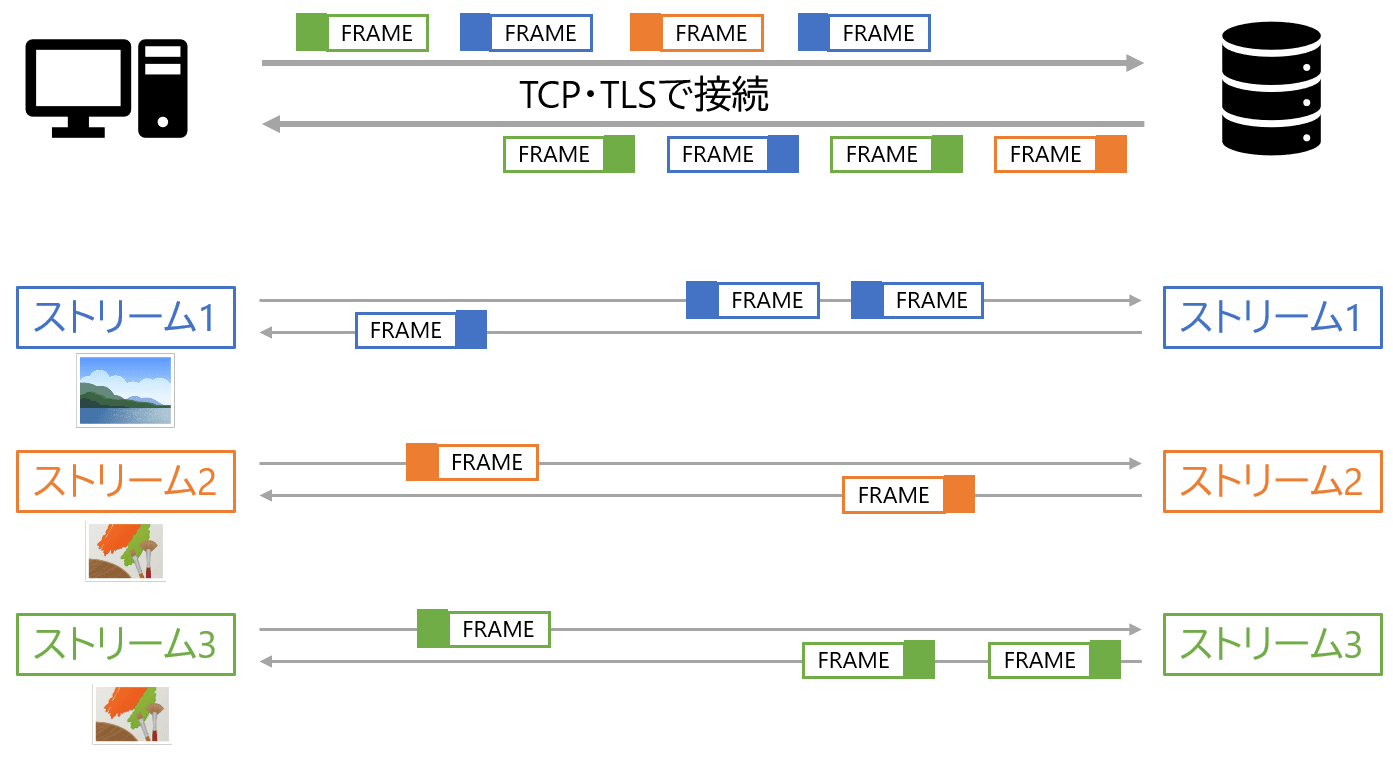
図のように、仮想的な通信路であるストリームに、例えば画像をリクエストして取得するデータを運ぶフレームが行き来しているイメージです。
HTTP/2をパケットキャプチャで観察
それでは例によってWireSharkでパケットを見てみましょう。

TCPとTLSのハンドシェイクの後、Magic, SETTINGS, WINDOW_UPDATE という3種類のフレームが送信された後、HTTP/1系でいうヘッダーに対応するHEADERSフレームが送信されています。 メソッドはHEADです。

リクエストのHEADERフレームはこのようになっています。
00 00 1f が長さ、 01 がフレームの種類 ( 0x01 はHEADERS)、 続く 00 00 00 01 が Stream Identifier で、
このリクエストフレームに対応するレスポンスのフレームのIDも同じ番号になっています。
続くデータが圧縮されたヘッダーのフラグメントで、これをデコードすると、 メソッド、パス、ステータスやその他のヘッダーとなります。
HTTP/2 のメリット
1つのTCPコネクション内で多重化できる
HTTP/1.x では、クライアント側の複数のポートを利用しTCPコネクションを多重に張ることで並列化を行っていると説明しました。 これによって、
- サーバー負荷の増大
- 輻輳制御の重複による帯域の使用効率低下
というデメリットが生じることを前半に説明しました。 HTTP/2は、1つのTCP接続で仮想的な多重化を行っているため、この2つのデメリットを解消しています。
クライアント-サーバー間の全体の輻輳制御はTCPのレイヤーに任せたうえで、 個々のHTTPメッセージの優先度をPriorityによって調節することができるようになりました。
ヘッダー圧縮
HTTP/1.x系の課題の1つとして、ヘッダーを圧縮できないというものがありました。 テキストベースのプロトコルであるHTTP/1.xは、ボディはgzipなどで圧縮できますが、ヘッダーはすべてプレーンテキストであるため、圧縮ができませんでした。 HTTPのヘッダーはCookieやUAなど同じ値を毎回送受信していることが多く、 これが圧縮できれば大きな効果が期待できます。
HTTP/2では、ヘッダーもバイナリで形式が定まっており、HPACKという形式で圧縮ができるようになりました。
まとめ
今回はHTTP/2について解説しました。次回は、現在標準化が進められているHTTP/3についての記事を書きたいと思います。